在深度伪造(Deepfake)技术飞速发展的当下,传统技术多聚焦于提升伪造内容的真实度,却严重忽视了实时性需求。在视频会议、在线直播等实时交互场景中,因人脸与声音伪造算法处理速度差异、数据差异及网络波动等因素,极易出现音视频不同步问题。更关键的是,现有同步技术依赖系统时钟或传输延时校准时间戳,无法适配伪造后音视频语义信息与特征分布的巨大变化,导致口型与声音错位,轻易暴露伪造痕迹。
合肥高维数据技术有限公司申请的发明专利《音视频伪造同步方法及其构成的伪造系统》(专利号:CN 115547357 B),正是针对这一核心痛点,提出了基于唇形-语音特征匹配的同步方案,实现伪造音视频的高效精准对齐。
技术核心:从“对齐时间戳”到“对齐语义”
本专利的核心突破在于,它不再简单粗暴地校准时间,而是智能地理解内容并进行匹配,可概括为“分段提取特征-匹配确定节点-精准对齐同步”三步法,具体流程如下:
分段特征提取:按200~500ms的预设时间对伪造视频分段,处理每段内多帧图像,通过提取唇形特征点、曲线拟合轮廓,计算外唇/内唇的距离、周长、面积等参数生成唇形特征向量,取多帧平均值作为该段唇形特征;同步提取对应时间段音频的语音特征,经预加重、分帧、加窗、快速傅里叶变换后,通过梅尔倒谱系数(MFCC)算法获取特征值,取平均值作为该段语音特征。
匹配点确定:利用唇形-语音匹配网络(如CRNN、ResNet等)计算两者匹配概率,确定匹配点。匹配点分为初始匹配点与非初始匹配点,初始匹配点通过计算前M个时间段(2~10个)的最大匹配概率确定,用于消除整体延迟;非初始匹配点在上一匹配点后,通过寻找音频信号幅值超阈值或达到预设间隔的时间点,在对应语音特征时间段范围内匹配最大概率唇形特征段获得。
精准对齐:基于初始匹配点将音视频沿时间轴整体平移完成第一次对齐;后续每确定一个非初始匹配点,以音频为基准对视频抽帧/补帧,或以视频为基准对音频加速/减速,完成分段精准对齐,保障实时同步。
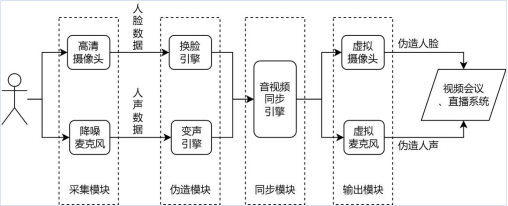
系统构成: 一站式的伪造与同步工作流
该系统构建了一个完整闭环:配套的音视频伪造系统则由采集模块(摄像头+麦克风)、伪造模块(换脸引擎+变声引擎)、同步模块、输出模块(虚拟摄像头+虚拟麦克风)构成,实现从数据采集、伪造生成、同步对齐到输出应用的全流程闭环。其技术创新亮点为:
语义级同步,适配伪造场景:摒弃传统时间戳校准思路,直接针对唇形与语音的语义关联特征进行匹配,完美适配伪造后音视频特征分布变化的场景,同步精准度更高。
分层对齐策略,兼顾效率与精度:初始匹配消除整体延迟,非初始匹配实现分段微调,配合200~500ms的合理分段(契合人类语速特征),在降低算力消耗的同时保障实时性,可满足直播、视频会议等高频交互需求。
模块化系统设计:换脸与变声引擎独立设置,便于算法更新迭代;输出端采用虚拟摄像头/麦克风,可直接对接现有视频会议、直播系统,无需改造原有设备,兼容性极强。
赋能多元场景,开启想象之门
隐私优先的远程协作:金融、法律、医疗等行业会议中,员工可使用虚拟形象发言,保护隐私而不失临场感,如证人保护、敏感访谈等需隐匿真实身份的场合。
沉浸式娱乐与创作:主播可实时变换为任何角色进行直播,制作高质量对口型多语种视频,极大降低创意门槛。
下一代人机交互:让虚拟客服、数字员工、元宇宙化身的口型表达自然精准,提升交流可信度与情感温度。
无障碍与创新传媒:为听力障碍者提供更准确的唇语辅助,或快速生成高质量的多语种新闻播报。

未来展望:负责任地塑造数字未来
高维数据此举不仅是技术突破,更是对深度伪造技术实用化、工具化、合规化发展路径的重要探索。展望未来,我们期待该技术:
借助区块链等技术,为生成内容添加可验证的合规标签,实现可追溯、可验证的合规深度伪造,促进技术向善。
与情感计算结合,实现表情、语调与内容的情绪同步。
向边缘计算轻量化发展,适配手机、XR眼镜等移动设备。
高维数据的音视频实时同步伪造系统,解决的不仅是一个技术痛点,更是拆除了深度伪造技术迈向大规模实时应用的最后一堵墙。它标志着我们从“能够伪造”进入了“能够自然、实时、可靠地运用伪造”的新阶段。在数字身份日益重要的明天,这项技术将为保护隐私、丰富表达、创新交互提供关键的基础设施,负责任地推动我们走向一个更灵动、更包容的虚拟融合世界。
- END -